


Understand MapReduce in Big Data
MapReduce is a processing technique and programming model for the distributed system. It is a simultaneous process and analyzes massive datasets logically into separate clusters. Hadoop can run MapReduce programs written in different languages- Java, Python, Ruby, and C++. While Map sorts the data, Reduce segregates it into logical clusters.
How MapReduce Works
MapReduce programs basically work in two phases:
- Map Phase
- Reduce Phase
In MapReduce programming input to each phase is in key-value pairs. The whole process goes through 4 phases: splitting, mapping, shuffling and reducing.
Let's understand it with a simple example.
Consider you have the following input data:
This quick brown fox jumps over the lazy dog.
A dog is a man's best friend.
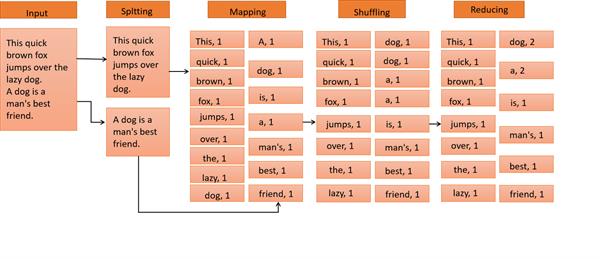
The input data goes through the following phases:
- Input Splits- Input to a MapReduce job is divided into fixed parts. It is a chunk of input that is consumed by a single map.
- Mapping- This is the 1st phase of the MapReduce program. In this phase assigned input is read from HDFS then it parses the input into key-value pairs. It applies the map function to each record. In the above example, the job of the mapping phase is to count the frequency of each word from the input splits.
- Shuffling- It fetches input data from all map tasks for the portion corresponding to the reduce task's bucket.
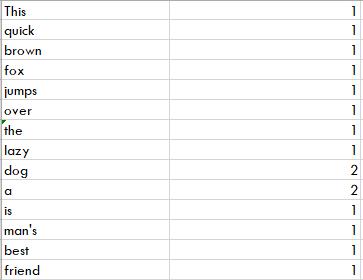
- Reduce Phase- In this phase output value from the shuffling is aggregated. It applies user-defined reduce functions to merged run. It summarizes the output from the shuffling phase and returns the final key-value pair.
In our example, this phase aggregates the output from the shuffling phase i.e., calculates the total occurrence of each word.
Essentials of MapReduce Phase
- The number of reduce tasks can be defined by users.
- Reduce phase cannot start until all mappers have finished processing.
- Each reduce task is assigned a set of recorded groups, that is, intermediate records corresponding to a group of keys.

CONTRIBUTE
MOBILE APP
