


A Comparative of Traditional RDBMS and HiveQL in Hadoop Enviromnent
Relational Database Management System (RDBMS) is the basis for structured query Language (SQL).This works for accessing and manipulating database. Its keyword based on the language but not any programming language like C, C++, Python etc. These days wide variety of data presents on the systems as well as fluctuate instantly on the systems. Various other database systems are present to handle huge amount of data. In this paper, we include various concepts of RDBMS like architecture, features, working areas and compare RDBMS with HiveQL. Hive is the easiest way to use of the high level Map Reduce frameworks. HIVE provides a SQL like language which is well known as Hive Query Language (HiveQL).
Introduction:-
RDBMS stands for Relational Database Management System help in managing data. A relational model can be represented as a table of rows and columns. The main difference between RDBMs databases and Hive is specialization. Hive is similar to traditional database by hold up the SQL interface but RDBMS is not a full database. Instead of calling Hive as database it can also be called as data warehouse. Hive apply schema on read time but RDBMS apply schema on write time. Hive is depending on the concept of Write once, Read many times but RDBMS is concert for Read and Write many times. RDBMS is suitable for dynamic data analysis but Hive is suitable for relatively static data is analysed.
Relational Database Management Systems(RDBMS) :-
These days RDBMS is commonly used for managing the data. The DBMS is depending on a model called relational model in this model data are stored in form of tables. The RDBMS consists of multiple tables that stored different data and combination of these tables together forms the one Relational Database Management System. RDBMS use SQL stands for Structured Query Language to approach the database.
Architecture of RDBMS:-
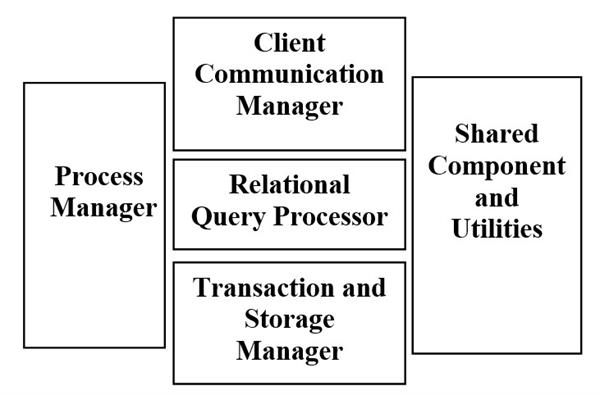
Feature of Relational Database Management System:-
1) Store Data In Tables:- Table is the major point of a database. Without table database would be of little or no use. If there is no table in the database then a data while look like a spreadsheet. A table contain columns and rows, rows move from left to right, columns move from top to bottom.
2) Data Structure: - In table we may have 10 columns or 100 columns in table. Columns characterize a fragment of data.
For example:- a piece of a data or a number etc. Database remains in rows and column and allow facility primary key to define different identification of rows.
4) It creates indexes for quicker data retrieval.
5) It also supports virtual tables from where data can be retrieved by using sql queries.
6) It helps in storing important data and simplifies queries
These features of RDBMS are the reason due to which it is used all around the world. In RDBMS software system it allows data to be stored in rows and columns.
Advantages of RDBMS
1) Easily Understood:
We all know that, with the help of table we can understand the data easily and it also help us to use it in an easy manner. The information stored in data can be easily checked as it is gathered in tables that contain rows and columns.
2) Protection:
Tables make the data private by splitting it into tables. The system make to use the information only to that user which is having the authorization for the data to use and view it is possible when user login with the relevant username and password. It is very important to make the information to be saved from the hackers as some information are very private which cannot be disclosed with the unauthorized user. So, RDBMS help in making the data secure from unauthorized user.
3) Language:
RDBMS supports a standard language SQL.SQL language is developed to allow user to perform ‘INSERT’, ‘UPDATE’, ‘DELETE’, ‘CREATE’, ‘DROP’ in table records. As syntax of SQL in easy to use and apply so it is mainly used.
4) Necessity:-
For future concern as information can easily added and join to the table that are already made and can be dependable with the already available information.
5) Stored Data:
In RDBMS the data is gathered only once and no need to change the records, more effective storage, easy to delete or change data and all the changes will happen with all the records which are link with the records entry.
Disadvantages of RDBMS:
1) Cost:
To use a RDBMS, special software is needed to be buying, and manage the information. If organization is large and you need a powerful database, then there is need to appoint a programmer to construct a relational database using SQL mean Structured Query Language and once the database is built to maintain that database you need to appoint database administrator.
2) Structure Limits:
Structure limits is the another disadvantage of RDBMS. In table some fields have limited character that can be entered by the user. Some relational database has limits on field lengths. You specify the amount to data to be fitted in the field at the time of designing the data.
3) Data complication:
Data is stored in various tables in RDBMS and they are linked together through shared key values.
4) Performance:
There is a need of highly developed processing power for solving complex queries. Desktop computers can control the database size and complication often entered in a small business, a database with outside data source or very difficult data structure may require more strong servers to give result in return within an aggregable feedback time.
5) Isolated collection of data can be make if large block of information are divided from each other.
Hadoop
Hadoop is an open-source framework to store and process Big Data in a distributed environment. It contains two modules, one is MapReduce and another is Hadoop Distributed File System (HDFS).
MapReduce: It is a parallel programming model for processing large amounts of structured, semi-structured, and unstructured data on large clusters of commodity hardware.
HDFS:Hadoop Distributed File System is a part of Hadoop framework, used to store and process the datasets. It provides a fault-tolerant file system to run on commodity hardware.
The Hadoop ecosystem contains different sub-projects (tools) such as Sqoop, Pig, and Hive that are used to help Hadoop modules.
Sqoop: It is used to import and export data to and from between HDFS and RDBMS.
Pig: It is a procedural language platform used to develop a script for MapReduce operations.
Hive: It is a platform used to develop SQL type scripts to do MapReduce operations.
HIVE:
To handle huge amount of data Facebook developed Hive in 2007 to control the volumes of data. As, Facebook data was increasing at a very fast rate as it evolve from 15 TB to 2 PB in a few years. So, initially Facebook data processing infrastructure was build using a RDBMS that was taking a long for daily jobs so there was a requirement of infrastructure that could scale along with data so they started using Hadoop but user was not familiar to Mapreduce. Hive is a Datawarehouse system built on top of Hadoop so you can create database table views and also you can access and query this data. Hive support provide Hive Query Language (HQL) which is also defined as Data Definition language (DDL) and Data Manipulation Language (DML) as in SQL. HQL queries implicitly translate into MapReduce jobs for execution. Hive support a device to project format onto Hadoop datasets.
What Hive is Not?
- Full database is not a hive.
- Row level insert, updates or deletes is not provided by hive
- Transactions and limited sub-query support id not supported by Hive.
- Hive is not100% sql
- Hive query optimization is still in evolving stage.
Hive Architecture:
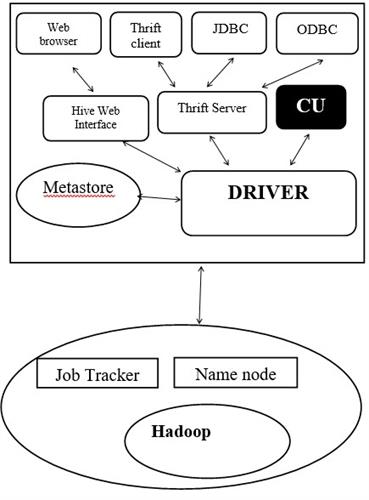
- HIVE sit on the top of Hadoop. On, Hadoop side we can see that we have HDFS and MapReduce. So, data resides on HDFS and using job tracker using MapReduce data analysis is done.
- The queries is submitted using 3 ways:-
- a) CLI stands for Command-line interface
- b) Hive web interface
- c) Thrift server
Thrift servers give you a flexibility to work with JDBC and ODBC connections. JDBC and ODBC are universal connectors anybody can access hive through outside using JDBC and ODBC.
- All the metadata of Hive is stored in METASTORE. It stores data in database, tables, columns etc. Metastore makes it possible to map file structure to a tabular forms.
- DRIVER : It function is whatever the query is submitted it compiles, optimizes and execute is convert into MapReduce whenever it run in HQL query and then it is send to the Hadoop world.
The data is divided in tables, partition and buckets when the data is stored in Hive as hive stores data in these manner but partitions and buckets are optional.
HIVEQL:
HiveQL is quite similar to SQL. It has data types like simple data type and collection data type. In simple data type we have integer, Boolean, float, string, binary type and in collection data type we have STRUCT, MAP and ARRAY.
HIVEQL COMMANDS:-
hive> SHOW TABLES;
Above Command is used to show tables
hive> CREATE TABLE students
(students INT, name STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’
STORED AS TEXTFILE;
Above command is used to create table related to students along with given conditions.
hive> DESCRIBE students;
Above command describe the contents of the table of student.
hive>LOAD data <LOCAL> inpath <file path> into table [table name]
The above Load command is used to move the data into corresponding Hive table. If the keyword local is specified, then in the load command will give the local file system path. If the keyword local is not specified we have to use the HDFS path of the file.
Hive>Truncate Table [db.name]. [table name]
Above command is used to truncate all the rows present in a table i.e. it deletes all the data from the Hive meta store and the data cannot be restored.
Table-1.1 Comparison between Hive and MySQL
|
Name |
Hive |
MySQL |
|
Description |
Data warehouse software for querying and managing large distributed datasets, built on Hadoop |
Widely used open source –Relational Database System(RDBMS) |
|
Primary database |
||
|
Secondary database |
||
|
Website |
||
|
Developer |
Apache Software Foundation. |
Oracle |
|
Date of release |
2012 |
1995 |
|
License |
Open Source |
Open Source |
|
Cloud Computing based |
No |
No |
|
DBaaS offerings |
|
|
|
Language support |
Java |
C and C++ |
|
Server operating system Support |
All OS with a Java VM |
FreeBSD |
Conclusion:
Hadoop manages huge amount of data in terms of storage and processes.SQL cannot handle unstructured data so that HIVEQL can work on massive data. Many organisations, uses Hadoop as data platform. HIVE must have supplement to provide usability and connectivity within the organisation by high level language support known as HiveQL.

CONTRIBUTE
MOBILE APP
