


Hadoop Vs Spark (Detailed Comparison)
There are multiple big data frameworks available in the market, choosing the right one is very difficult. The classical approach of comparing the pros and cons of all the big data frameworks is not beneficial as all the frameworks are important and should be considered according to the business perspective.
Apache Hadoop
Hadoop is an open-source framework that allows you to store Big Data in a distributed environment so that you can process it parallelly.
HDFS
HDFS is a distributed file system that provides access to data across Hadoop clusters. It manages and supports analysis of a very large volume of Big Data. It is very economical, has high fault-tolerant and high throughput.
NameNode
It is the master daemon that maintains and manages the data nodes. It maintains and executes file system namespace operations such as opening, closing, and renaming of files and directories that are present in HDFS. It also maintains the metadata of the files stored in the cluster.
DataNode
These are the slave node which runs on each slave machine. The actual data is stored in this node. It is responsible for storing and maintaining the data blocks. It also retrieves the blocks when asked by the clients or the NameNode.
Secondary NameNode
Secondary NameNode server is responsible for maintaining a backup of the NameNode server. It maintains the edit log and namespace image information in sync with the NameNode server. There can be only one Secondary Namenode server in a cluster.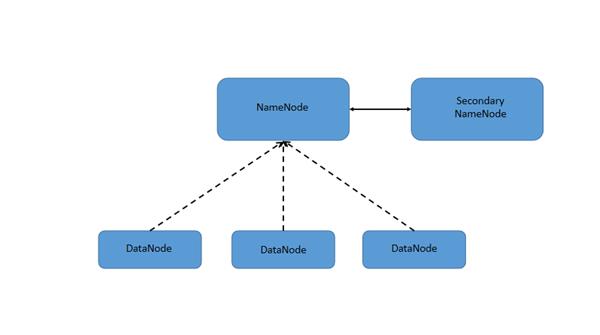
Apache Spark
Apache Spark is an open-source distributed cluster-computing framework. It is a framework for real-time. It is a fast, in-memory processing engine with elegant and development APIs to allow data workers to efficiently execute machine learning, streaming or SQL task that require fast iterative access to datasets. It provides up to 100 times faster performance for few applications with in-memory primitives, as compared to the two-stage disk-based MapReduce paradigm of Hadoop.
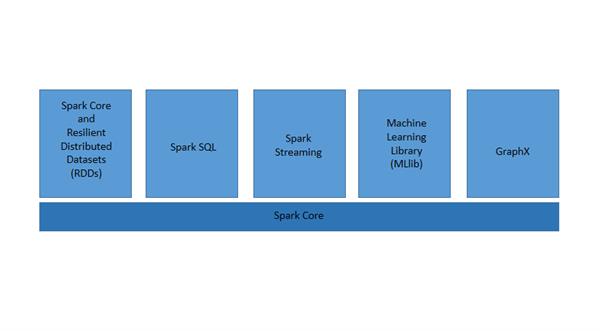
Spark Core and RDDs
Spark Core is the base of the whole project. It provides memory management, fault recovery, scheduling, distributing and monitoring jobs on a cluster.
Resilient Distributed Datasets(RDD) is a fundamental data structure of Spark. It is an immutable and partitioned collection of records, which can only be created by operations like map, filter, group by, etc. RDD can only be created by reading data from a stable source such as HDFS or by transformations on existing RDDs.
Spark SQL
Spark SQL brings native support for SQL to Spark and streamlines the process of querying data stored both in RDDs and in external sources. It introduces schemaRDD, which can be manipulated. It supports SQL with ODBC/JDBC server and command-line interfaces.
Spark Streaming
It leverages the fast scheduling capability of spark core. It ingests data in small batches and performs RDD transformation on them. It enables high-throughput and fault-tolerant stream process of live data streams.
MLlib
MLlib stands for Machine Learning Library. Spark MLlib is used to perform machine learning on Apache Spark. It is nine times faster than the Hadoop disk-based version of Apache Mahout.
GraphX
GraphX is the Spark API for graphs and graph-parallel computations. It extends the spark RDD with a Resilient Distributed Property Graph. It gives an API and provides an optimized runtime for the Pregel abstraction.
As we can see, Spark comes packed with high-level libraries, including support for Java, Python, R, Scala, etc. These standard libraries increase the seamless integrations in a complex workflow. It allows various sets of services like MLlib, GraphX, SQL, Streaming services, etc. to increase its capabilities.
How Spark is better than Hadoop?
1. In-memory Processing
Sparks does in-memory data processing which is much faster than Hadoop two-stage disk-based MapReduce paradigm. It is 100x times faster than Hadoop when data is in the memory and 10x faster when data is in the disk.
2. Stream Processing
Apache Spark supports stream processing, which involves continuous input and output of data. It enables high-throughput and fault-tolerant stream process of live data streams.
3. Lazy Evaluation
Apache Spark starts evaluating only when it is absolutely needed. This plays an important role in contributing to its speed.
4. Fewer Lines of Code
Spark is written in both Java and Scala but its implementation is done in Scala, so the number of lines is relatively lesser in Spark when compared to Hadoop.
Hadoop MapReduce is good for
The tasks at MapReduce is good are:
1. Linear processing of huge data sets
Hadoop MapReduce allows parallel processing of huge amounts of data. It divides the large datasets into smaller ones so that it can be processed separately on different data nodes and gathers the result automatically from all the nodes to return a single result. In case the resulting dataset is larger than available ram, Hadoop MapReduce may outperform Spark.
2. If instant results are not required
Hadoop MapReduce is a good and economical solution for batch processing.
Spark is good for
The tasks at Spark is good are:
1. Fast Data Processing
In-memory processing makes Spark faster than Hadoop MapReduce.It is 100x times faster than Hadoop when data is in the memory and 10x faster when data is in the disk.
2. Iterative Processing
If the task is to process the data again and again - Spark excels Hadoop MapReduce. Spark's RDDs enable multiple map operations in memory, while Hadoop MapReduce has to write temporary results to a disk.
3. Machine Learning
Spark has MLlib - a built-in machine learning library, while Hadoop needs a third-party to provide it.
4. Graph Processing
Spark’s computational model is good for iterative computations that are typical in graph processing. GraphX is the Spark API for graphs and graph-parallel computations.
5. Near real-time processing
If a business demands immediate results, then they should go for Spark and its in-memory processing.
Which framework to choose?
It depends on the business demand which framework to choose. Linear processing of huge datasets is the advantage of Hadoop MapReduce, while Spark delivers fast performance, iterative processing, real-time analytics, graph processing, machine learning and more. In many cases, Spark may outperform Hadoop MapReduce. The best thing is that Spark is fully compatible with the Hadoop ecosystem and works smoothly with the HDFS.

CONTRIBUTE
MOBILE APP
