


What is AWS Redshift Spectrum or Amazon Redshift Spectrum
Amazon Redshift Spectrum
Amazon Redshift Spectrum is a feature inside Amazon Web Services' Redshift data warehousing administration that lets a data analyst lead quick, complex analysis on objects stored on the AWS cloud.

With Redshift Spectrum, an analyst can perform SQL queries on data stored in Amazon S3 buckets. This can set aside time and cash since it kills the need to move data from a storage service to a database, and rather straightforwardly queries data inside an S3 bucket. Redshift Spectrum likewise grows the extent of a given query since it reaches out past a client's current Redshift data warehouse nodes and into enormous volumes of unstructured S3 data lakes.
Key Features
With Redshift Spectrum, you will have the freedom to store your data in a huge number of formats, so it is accessible for processing at whatever point you need it. Here are a couple of Spectrum's key features:
- Instant queries inside your favorite BI tools without the need for loading and changing your data stored in Amazon S3
- Scaling processing across a huge number of nodes with separated cluster storage and computing
- Quick outcomes with Amazon Redshift query optimizer that limits data scanned in AWS S3 to improve query speed
- A follow through on per-query cost which permits you to pay just for the queries you run
How does Amazon Redshift Spectrum Work?
Amazon Redshift Spectrum works on data stored on AWS S3 which implies that you can process the data utilizing other AWS services. As a matter of fact, Amazon Athena data catalogs are utilized by Spectrum by default. So on the off chance that you use Athena, all you have to do, to begin with, Spectrum is to provide an authorization to access your data files in S3 and data catalog in Athena. The data records are similar ones that you would use for different applications and AWS administrations.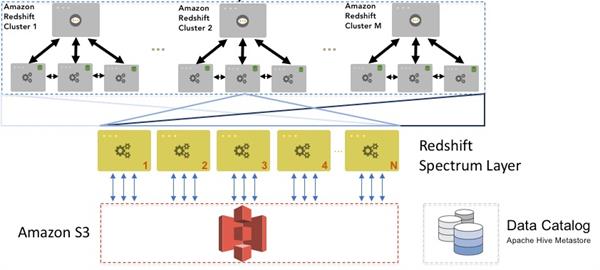
There are a couple of things you need to take into consideration when beginning to work with data files for queries in Amazon Redshift Spectrum:
-
External Tables
To query data on Amazon S3, Spectrum utilizes external tables, so you'll have to characterize those. Syntax to query external tables is the equivalent SELECT syntax that is used to query other Amazon Redshift tables. One thing to make reference to is that you can join created an external table with other non-external tables dwelling on Redshift utilizing JOIN command. -
File Formats supported by Spectrum
Amazon Redshift Spectrum supports structured and semi-structured data formats that incorporate Parquet, Textfile, Sequencefile, and Rcfile. Amazon suggests utilizing a columnar format since it will permit you to pick just the columns you need to transfer data from S3. -
Data Compression
Compressing your data files permits you to diminish storage space, improve performance, and minimize costs and recommended by Amazon. Spectrum supports gzip, snappy, and bz2 compression files. -
Optimization for massively parallel processing (MPP)
To viably work with complex queries running on a huge amount of data, you need to optimize your data for parallel processing. For best performance, Amazon recommends to break big files into numerous small chunks (from 100 MB to 1 GB) and store them in the same folder. It is likewise suggested to keep them all about a similar size because a major distinction in file sizes may cause uneven distribution of the remaining task at hand.
Pricing
Amazon Redshift Spectrum follows a per-use billing model, at $5 per terabyte of data pulled from S3, with a 10 MB minimum query. AWS suggests that a client compresses its data or stores it in a column-oriented form to save money. Those expenses exclude the Redshift cluster and S3 storage fees.
To know about what is basically Amazon Redshift you can visit the following link: What is Amazon Redshift

CONTRIBUTE
MOBILE APP
